Compiling for the EVM: Codegen for Stack Machines
The EVM (Ethereum Virtual Machine) is a stack machine: instead of registers, instructions operate implicitly on a stack. While most books on compilers have a chapter on register allocation, there’s surprisingly little material about code generation for stack machines, which seems to be considered generally straightforward. Yet, in the context of the EVM, programmers see the Solidity compiler struggle with its infamous “stack too deep” error. Is code generation somehow harder for the EVM’s stack? In this article, we’ll explore this question, trace the cause of the error, and try to understand what makes the EVM special as a compilation target.
The compiler’s job
Given a well-formed source program, a compiler’s job is to produce an equivalent lower-level program, usually optimized to be efficient in some dimension (like performance or size). To do this, the program is read by the compiler and transformed through different representations of its behavior, eventually arriving at a form that is directly translated into the language of the target machine. This last phase is known as code generation, or codegen.
Implicit in the description above is the fact that every well-formed program should be able to be compiled. Under this framework, if a valid program doesn’t compile it’s either that the language’s notion of well-formedness is incomplete (e.g., the type system should be stricter), or that the compiler isn’t fully doing its job. This is currently the case for the Solidity compiler, where some programs fail to compile with a particular codegen error: “stack too deep”.
If this were caused by an inherent limitation of programs on the EVM, it would be appropriate to define well-formedness in a way that reflected the machine constraints. However, compilers for other EVM languages like Vyper don’t have this error and demonstrate that it’s avoidable. In Solidity, it’s caused a lot of pain for developers, it feels inscrutable, and fixing it requires refactoring code in unintuitive ways. Reliably ensuring compilability should be one of the goals of the compiler, so let’s try to understand what’s getting in the way of that goal.
Solidity codegen
The Solidity compiler has two modes that approach codegen differently: legacy and “via IR”. The difference is in the representations that code goes through before being translated into EVM bytecode. Both modes create an AST (Abstract Syntax Tree) of the source code as the first step, a direct syntactical representation. Legacy codegen produces bytecode directly from this AST, whereas “via IR” transforms it into an IR (Intermediate Representation) that is simpler and easier to manipulate and then produces bytecode from the IR.
Legacy codegen is still the default and predominant choice, and the way it works is extremely simple. After analyzing the entire source code and collecting some information, the compiler begins to walk through the AST of a contract, sequentially producing bytecode for each construct it visits. The tree is walked hierarchically, so imagine it descending from the contract’s top level, into a function, into a statement in the function body, into an expression, and into its subexpressions; out of a statement, it moves to the next statement, and so on.
For the purpose of understanding the use of the stack we can focus on how function bodies are processed, specifically the statements and expressions within them. The generated code for these constructs uses the stack with a very simple and strict discipline.
Visiting an expression generates code that leaves the value of that expression at the top of the stack. For example, the number literal 42 will generate the instruction push1 42. More complex expressions are processed in post-order traversal. For example, 40 + 2 will first visit 40 and emit push1 40, then visit 2 and emit push1 2, and finally emit add corresponding to the + operation (assume unchecked arithmetic). This sequence of instructions leaves the result of 40 + 2 at the top of the stack. Note that, during the evaluation of an expression, many intermediate values needed to evaluate subexpressions may be at the top of the stack, forming a distinct section of the stack dedicated to expression evaluation.
Unlike expressions, statements don’t produce values, they’re meant for their side effects only. An important class of side effect is the declaration and use of local variables, which are kept on the stack in a special section behind that of expression evaluation. Within this section, local variables are kept in a fixed order, with newer variables closer to the top of the stack. Variable declaration statements grow this section by pushing a new value, whereas other statements keep it the same size. For example, the declaration uint256 x; will generate the instruction push0 to initialize the variable to zero and label the new top of the stack x.
We should now be able to imagine the code that is necessary to update the value of a local variable. For any subexpression e, for the assignment expression x = e the compiler should first generate the code to evaluate e, resulting in its value at the top of the stack, and then code to move this value to the stack location for x, discarding the previous value of the variable.
Putting this all together into one example, the sequence of two statements uint256 x; x = 42; will produce the sequence of instructions push0, push1 42, swap1, pop. This is illustrated in the image below along with how the stack progresses after each step, highlighting the two sections that compose it: one holding the current value of variables in scope (in blue) and another holding the expression being evaluated (in green), which is empty between statements.
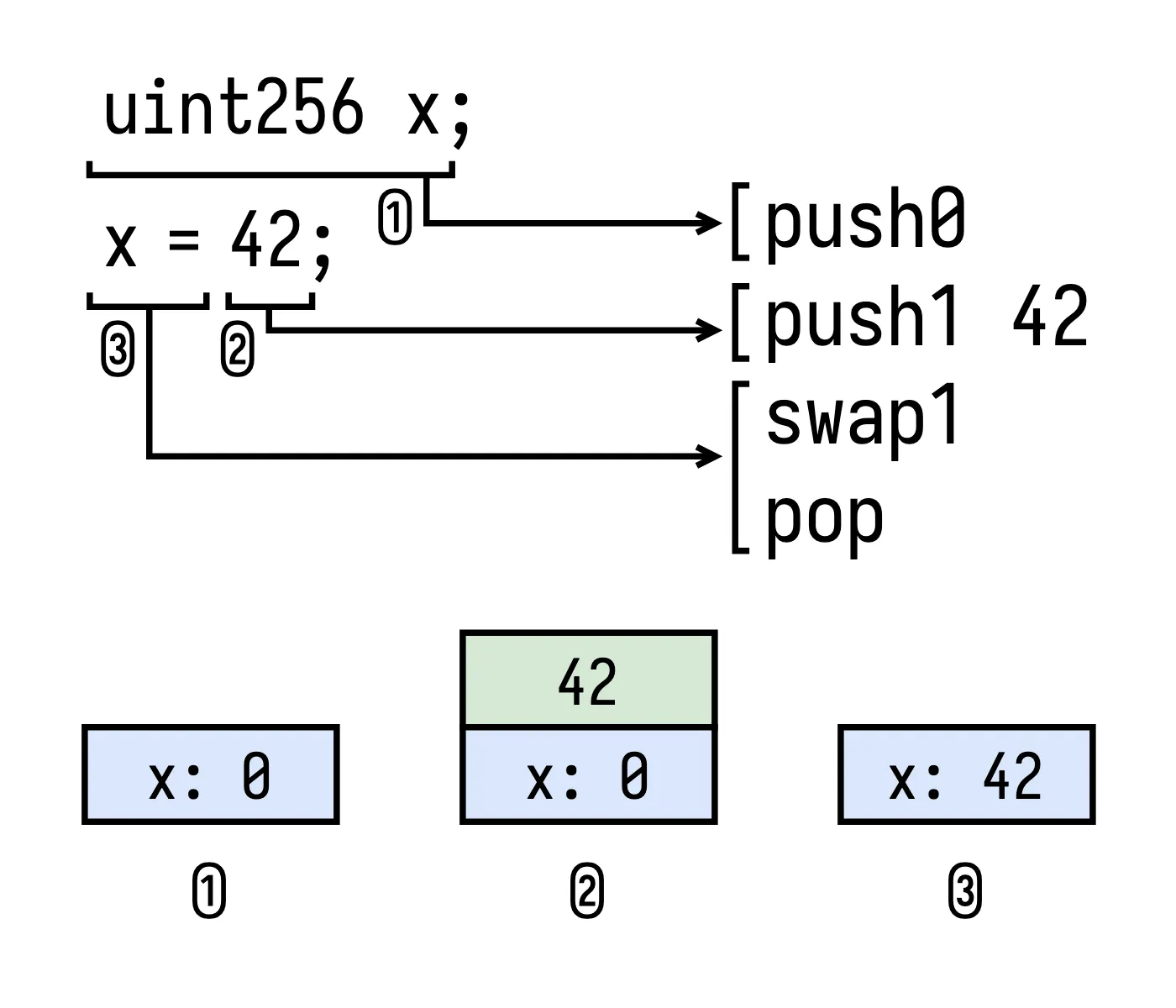
Finally, we should now see where “stack too deep” can arise. A variable reference should be compiled to code that looks up the current value of the variable and puts it at the top of the stack. This should be done by a dup instruction that reaches back in the stack to the current offset where the variable would be found. However, dup (and swap) can only reach back to offset 16, and Solidity’s stack discipline can require an offset that’s arbitrarily large, not only depending on the number of local variables but also on the number of subexpressions that may be in the top section of the stack the moment the variable reference is processed. When this happens, the compiler is unable to proceed and aborts compilation.
As it turns out, this way of using the stack looks a lot like what we’d see from compilers targetting other stack-based VMs. However, unlike Solidity, they don’t have “stack too deep” issues. What exactly is the difference with the EVM? And is there anything we can learn from those other environments?
The stack, elsewhere
The EVM is not at all alone as a stack machine among virtual machines. To name a few big ones, the JVM, WebAssembly, and Microsoft’s CLR are all stack-based. Even programs on register-based machines have a stack. Common among all of these is that the stack is used roughly in Last-In-First-Out fashion, but the precise access patterns and capabilities differ.
Most stack-based VMs have, conceptually, two separate stacks that are used for different purposes: the operand stack and the frame stack. The operand stack is where all machine instructions implicitly get their arguments and leave their results. The centrality of this data structure is what makes these stack machines. Instructions in register-based machines instead rely on a fixed set of addressable registers for that purpose.
The frame stack is present in both of these architectures, as it’s necessary to keep track of function calls during execution. However, we should note a difference between how it exists in VMs and in programs running directly on hardware. The VMs provide a structured interface to the frame stack, in the sense that programs can access and manipulate it only in specific ways. On hardware, on the other hand, the frame stack is manually built by the program on RAM and access isn’t restricted any more than other memory locations, giving a lot of freedom to programs and compilers. Because a program on a VM doesn’t have this freedom, the VM needs to make sure the structured interface it provides is sufficient and efficient enough for the job that compilers have to do.
Interaction with the operand stack is also mediated by a structured interface, and in fact for all of these stack-based VMs it’s an extremely limited one. For example, in WebAssembly there’s no way to duplicate or reorder elements on it. It would be very difficult to do interesting things exclusively on the operand stack, so to make up for this limitation each frame in the frame stack has abundant space for local variables, and there are instructions to read and write to locals in any order.
We should now see that the EVM stack is an operand stack just like the one on these machines. Even though there are instructions to duplicate and reorder elements, they’re limited to the top 16 stack positions, so it’s still a limited interface. It’s possible to do more interesting things with this stack than with WebAssembly’s, but it’s not sufficient to ensure reliable compilability.
Frame locals are a feature of all stack-based VMs I’ve looked at, and they make codegen straightforward. The procedure followed by Solidity’s legacy codegen can be used for these VMs without the same compilability struggles, keeping local variables not on the operand stack but instead as true locals in the separate frame stack. In this case the approach is reliable because there’s abundant space for locals and reading or writing to one will work no matter the size of the operand stack.
Frame and operand stacks have fundamentally different requirements. Whereas other stack-based VMs recognize the limits of the operand stack and provide a built-in notion of local variables in the runtime, the EVM does not. So is there anything else we can use?
A peculiar VM
We should first clarify if the frame stack has an analogue in the EVM. In this context, we need to consider two different kinds of function calls: external calls between contracts, and internal calls within one contract. There is in fact a built-in frame stack, but it’s designed to keep track of external calls and not to structure the internal execution of a contract. One of the notable characteristics of running code on the EVM is that every instruction is priced and charged to the user, so developers aim to make contracts as efficient as possible. Internal calls can in principle be cheaper and simpler than external ones, so the native frame stack isn’t used for these. For the purpose of code generation, we’ll ignore it and assume we’re within one frame.
In a frame, we find an instance of the stack we’ve been discussing. Solidity uses this stack like a frame stack for internal calls, but we’ve shown it’s insufficient, as it’s not able to implement a reliable local variable store. The only way to resolve this issue is to place all or some values outside the stack, namely in memory.
Memory should sound familiar: as mentioned previously, programs on hardware computers construct a frame stack on RAM, that is, memory. Technically, a contract on the EVM could do the same thing, and Solidity has in fact explored doing something like this. The issue lies in the cost and structure of memory.
RAM is short for Random Access Memory, which implies a uniform cost to access any memory location. Of course the cost is affected by caches, and there is an extra cost to allocate a new portion of memory, but these aren’t a function of the memory location. In the EVM, memory is not random-access to the same degree, because prior to accessing a location the size of memory has to be expanded up to that point, and this expansion has a cost that grows with the size. This has two implications.
First, if we build a frame stack in memory, the cost of each frame would increase with stack depth, due to memory expansion. On the other hand, the cost of expanding the native stack is constant, so it should be preferred if possible. Since the stack has a depth limit of 1024 elements anyway, we could consider a frame stack of bounded size in memory and say that the amortized cost for each frame comes out constant as well, but it would be more expensive, so the preference stands.
Second, the contract may want to use memory for other purposes, like a heap rather than a stack, and this mixed use would make memory allocation more complex. In true RAM, sharing memory for heap and stack is simple by putting each on different ends of the RAM and making them grow in opposite directions. This pattern cannot be replicated as is in EVM memory because of expansion costs.
It’s possible to use memory to avoid “stack too deep”, but it’s not as simple as porting ideas from other environments. Solidity has been moving towards this in recent versions, though it’s only implemented for IR codegen. We’ll look at the details of that implementation in a future article. Vyper has avoided the error by relying on statically allocated memory locations for all local variables, but as a consequence it disallows cyclic function calls, resulting in a programming language of limited expressiveness. One could argue that smart contracts should be simple enough that they never run into this limitation, but my belief is that we should aim for maximum expressiveness if we can unlock it.
Conclusion
It’s possible to design a compiler that fully avoids “stack too deep” errors, but there are constraints in the EVM that make it difficult to come up with a good general-purpose design. We’re limited in what we can learn from other stack-based VMs, because the costs and capabilities provided by the VMs are different. The design space in general is different from compilers that target such VMs or even more so traditional hardware computers, and it requires special considerations and possibly new techniques to unlock the full expressive power of contracts on the EVM.
Some readers may have noticed that legacy Solidity codegen can be quite inefficient in its use of the stack. In an upcoming article we’ll turn our focus to stack efficiency, explain how Solidity’s new IR codegen works, and try to understand what improvements it can deliver and where it may still fall short.